內容目錄
反爬蟲機制的升級,網站完全不給爬
以前大多數網站只需要在啟動時添加簡單的幾個 ChromeOptions,大多數時候只要爬蟲請求的不要太頻繁都不會有事。
ChromeOptions option = new();
option.AddAdditionalOption("useAutomationExtension", false);
option.AddArgument("--disable-blink-features=AutomationControlled");
option.AddArgument($"--user-agent={ua}");
var driver = new ChromeDriver(option);最近幾個月爬取資料、執行自動化任務時經常會遇到一些惱人的反爬蟲機制,而且偵測爬蟲的手段一直不斷在升級,從早期的判斷 UserAgent 與 window.navigator 是否包含 webdriver 屬性,到現在甚至有探測瀏覽器支援的編解碼器 (media.codecs) 來判斷是否為爬蟲…,不是長年專注這塊領域的根本玩不贏大公司設計的反爬蟲機制。
現在像是 蝦皮、露天、DCard 等網站都進行了非常嚴格的反爬蟲機制,即使透過鍵盤輸入正確的帳號密碼、人工點擊 驗證你是人類 的按鈕、完成滑塊拼圖、完成兩步驟驗證,上述都做完了它也不會讓你登入,永遠會卡在最後一步無限迴圈。
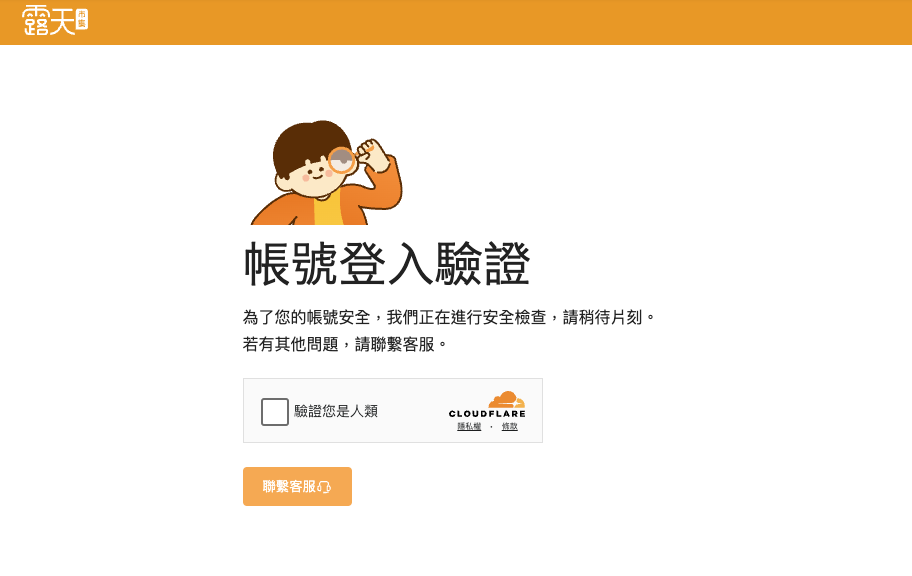
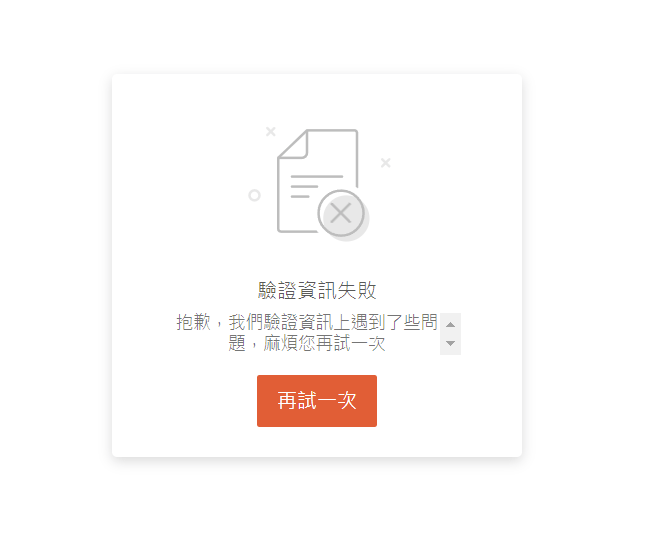
Selenium 是怎麼被偵測出來的
每個網站偵測的項目的不盡相同,不過有兩個滿重要的網站可以作為指標
- Intoli.com 的測試要幾乎要全綠燈,並且 Fingerprint 要出的来
- reCAPTCHA 分數至少大過 0.7


如何辦到這兩個條件這問題困擾了我一陣子,無論怎麼喬都還是會被 Cloudflare 與 reCAPTCHA 偵測出來,直到發現一個叫做 Puppeteer 的專案,他是一個 Node.js 的爬蟲套件,其中裡面有個 Stealth 插件很好的辦到了這件事,不過這畢竟不是 Selenium 的專案沒辦法直接拿來使用,還需要經過處理才能借來用。
在 puppeteer-extra 中生成 stealth.min.js
- 首先,先把整個 puppeteer-extra 專案給 clone 下來,並透過終端機開啟資料夾
- 依序輸入以下命令建置方案並產生 stealth.min.js
# step.0 安裝 yarn,如果已經安裝可以略過
brew install yarn # Mac 可以透過 Homebrew 安裝
npm install --global yarn # Win 可透過 npm 安裝
# step.1 建置方案
yarn # 安裝依賴套件
yarn bootstrap # 將依賴套件連接
yarn build # 建置方案
# 建置的過程中跳出 error Command "build" not found. 可以無視他
# 報錯不影響下一步驟
# step.2 產生 stealth.min.js
cd packages/extract-stealth-evasions # 前往 packages/extract-stealth-evasions 資料夾
node index.js # 產生 stealth.min.js 載入網頁前,先執行 stealth.min.js 隱藏特徵
這個 stealth.min.js 可以在 Selenium webDriver 初始化後,透過 Chrome DevTools Commands 設定在每個頁面載入前執行,就可以把 Selenium、webdriver 的相關特徵隱藏的很徹底,甚至連 headless 模式也不會被發現。
// 初始化 webdriver
var driver = new ChromeDriver();
// 讀取 stealth.min.js
var reader = new StreamReader(@"Models/Selenium/stealth.min.js");
var js = reader.ReadToEnd();
// 執行 Chrome DevTools Commands
// 設定 Page.addScriptToEvaluateOnNewDocument
Dictionary<string, object> dict = new () { { "source", js } };
driver.ExecuteCdpCommand("Page.addScriptToEvaluateOnNewDocument", dict);透過這方式啟動的 webDriver 就能順利通過 Intoli.com 測試,並且 reCAPTCHA 也能獲得不錯的分數,這樣幾乎就能順破解大多數網站的反爬蟲機制。